

Industry attributes

Other attributes
Generative AI refers to a set of deep-learning technologies that use existing content, such as text, audio, or images, to create new plausible content that previously would have relied on humans. Generative AI is driven by unsupervised and semi-supervised machine learning algorithms capable of identifying underlying patterns present in the input to generate similar content, delivering innovative results without human thought processes or bias. Well-known examples of generative AI models include Open AI's GPT-3 (text generator) and DALL-E (text-to-image generator) and Google's BERT (language model). Various techniques are utilized by generative AI algorithms, and the two most widely used models are generative adversarial networks (GANs) and transformer-based models. Another popular technique is variational auto-encoders (VAEs).
Generative AI is a broad term that can be used to describe any type of artificial intelligence using unsupervised learning algorithms to create new digital images, video, audio, text, or code. While the term is often associated with deep fakes and data journalism, it is also playing an increased role across a number of fields. Examples include automating repetitive processes for digital image or audio correction, a tool for rapid prototyping in manufacturing, and improving data augmentation within robotic process automation. Other potential generative AI use cases include the following:
- Logistics—the conversion of satellite images to map views to investigate new locations
- Marketing—the generating of advertising messages and client segmentation to predict the response to different content
- Healthcare—the conversion of x-rays or CT scans into photo-realistic images and the earlier diagnosis of dangerous diseases, such as cancer
- Travel—the improvement of face identification and verification systems at airports based on past photos
Generative AI technologies have generated debate about the limits of technology and how it impacts society. The ability to generate content previously requiring human creativity has led to concerns that it will replace many human roles in the workforce. Often technologies like generative AI incorporate a human-in-the-loop (HITL) element.
Apps built on top of the large generative AI models often exist as plug-ins for other software ecosystems. Examples include code generation tools for an IDE, image generation plug-ins in Figma or Photoshop, and bots to post generated content on social media. However, stand-alone generative AI web apps also exist; these include Jasper and Copy.ai for copywriting, Runway for video editing, and Mem for note-taking.
Until recent developments, most AI learning models were characterized as discriminatory, i.e., they use what is learned during training to make decisions about new inputs. In contrast, generative AI models generate synthetic data to pass a Turing Test. This means it requires more processing power than discriminative AI and is more expensive to implement. During the training process, generative AI models are given a limited number of parameters, with the model forced to draw its own conclusions about the most important characteristics of the data provided. Once the generative AI determines the data's fundamental properties, it utilizes various techniques (e.g., GANs, VAEs, or transformer-based models) to improve output accuracy.
Primarily belonging to supervised machine learning tasks, discriminative modeling classifies existing data points into respective categories. It does this by dividing input data based on some set of features. These distinctions can be used to predict what category certain data belongs to. Reducing a dataset to only two features and two categories allows for a 2-dimensional representation with a line defining the decision boundary or discrimination criteria used to separate the examples provided:

Representation of a discriminative modeling algorithm with only two parameters and two categories.
This can be written mathematically as the probability of being a specific category (y) when the features (x) are present, p(y|x).
Generative modeling does the opposite of discriminative modeling, predicting and generating features given a certain categorization. If discriminative algorithms define the relationship between features and the classification they suggest, generative algorithms produce examples of chosen features given the classification. Using the same definitions as above, discriminative modeling investigates the relationship between x, y, and p(x|y). Generative modeling produces values of x for a given categorization or, put another way capturing the probability of x and y occurring together, p(x,y). Predicting the distribution of individual classes and features, not the boundaries between them.
By generating examples, generative AI can help answer the question of what fundamentally defines each category. Learning features and their relationship to other parameters to produce an accurate representation of the chosen content, for example, an image or piece of audio. Generative algorithms aim to be a holistic process, modeling without discarding any information.
Generative adversarial networks (GANs) are generative models made up of two neural networks working against each other:
- Generator—This is a neural network creating fake inputs or samples from a random input vector (list of variables with unknown values)
- Discriminator—This is a neural network that determines if the sample provided is real or not (i.e., is it a sample from the generator or a real sample)
Both the generator and discriminator are often implemented as Convolutional Neural Networks (CNNs), in particular when they are designed to work with images. The discriminator returns a probability (between 0 and 1) rather than a binary response. The closer the returned value is to 0, the more likely the sample is to be a fake.
The contest between the two neural networks takes the form of a zero-sum game, where one gain is at the other's expense. The adversarial nature of GANs is due to the game theory scenario whereby the generator and discriminator compete. In this scenario, there will always be a winner and a loser. The losing network is updated, while its rival remains unchanged. GANs can be considered successful when the generator begins to create samples convincing enough to fool both the discriminator and humans.
Both neural networks are trained in alternating cycles. This means the generator is constantly learning to produce more realistic data, and the discriminator improves at differentiating fake data from real data. This competition works to improve the performance of both neural networks.

Diagram of GAN operations.
GANs are semi-supervised learning frameworks, meaning they use manually labeled training data for supervised learning and unlabeled data for unsupervised learning approaches. This allows GANs to build models that leverage labeled data to make predictions beyond the labeled data. Benefits of this semi-supervised structure include the application of generative AI against supervised learning. Examples include the following:
- Overfitting—Generative models typically have fewer parameters making it harder to overfit. They also engage with a tremendous amount of data due to the training process, making them more robust to occlusions.
- Human bias—Human labels are not apparent as in the supervised learning approach. Instead, learning relies on the data properties, avoiding spurious correlations.
- Model bias—Generative models produce samples dissimilar to those in the training data.
GANs were invented in 2014 by Ian Goodfellow and his colleagues at the University of Montreal. Their architecture was first described in a paper titled "Generative Adversarial Networks." Since they were introduced, there has been significant research and practical applications of GANs, and they have become the most popular generative AI model.
Transformer-based models are deep neural networks that can learn context and meaning by tracking the relationships in sequential data, such as the words in this sentence. They are commonly used in Natural Language Processing (NLP) tasks. Examples of transformer-based generative AI models include GPT-e, LaMDA, and Wu-Dao. These imitate cognitive attention and differentially determine the significance of the input data parts. Through training, they can understand the language or image, learn classification tasks, and generate texts or images from large training datasets.
Transformers get their name as they transform one sequence into another. They are a subset of semi-supervised learning models, meaning they are trained in an unsupervised manner with a large unlabeled dataset, which is then fine-tuned for better performance using supervised training. Typically they consist of two parts:
- Encoder—This extracts features from an input sequence, converting them into vectors. Examples of these vectors for text include the positioning of each word within a sentence and the semantics used.
- Decoder—This takes the encoder's output and derives context to generate the output sequence.
Both consist of multiple encoder blocks piled on top of one another, with the output of each becoming the input for the next. By iterating encoder layers, transformers utilize sequence-to-sequence learning, where a sequence of tokens predicts the next component of the output. Through attention or self-attention mechanisms, transformers can identify subtle ways that even distant data elements in a series create dependencies with one another. These techniques decipher the context around items within the input sequence, so rather than treating each element separately, the transformer attempts to bring meaning to each.
Transformers for generative AI were first described in a 2017 paper from Google titled "Attention Is All You Need." The team from Google describes a new architecture based solely on attention mechanisms, entirely removing the use of recurrence and convolutions.
VAEs design complicated generative models of data, fitting them to huge datasets. They have multiple uses, including generating images of fictional people and producing high-resolution digital artwork. VAEs provide a probabilistic manner to describe observations or inputs in latent space. Therefore, rather than building an encoder to output a single value describing each latent state attribute, VAEs formulate an encoder to describe the probability distribution for each latent attribute. These encoders produce the input as a compressed code, from which the decoder reproduces the initial information. When trained correctly, the compressed code representation of the input stores data distribution in a much smaller dimensional representation.
VAEs were defined by Kingma et al. in 2013 and expanded by Rezende et al. in 2014.
Generative AI models are capable of generating content in a range of domains:
- Text—These are the most advanced domain with models capable of producing generic short and medium-length writing. Typically the generative AI models would generate the first draft or be used for iteration.
- Code—These help improve developer productivity and make coding more accessible to non-developers. Examples include GitHub CoPilot.
- Images—These are a newer domain capable of generating lifelike images of people who don't exist or generating digital artwork.
- Speech—Examples have been around in the form of home hubs and digital assistants with consumer and enterprise applications under development.
- Other—These include video, 3D models, audio, music, gaming, and robotic process automation.
In September 2022, VC firm Sequoia Capital published a summary of the generative AI application landscape showcasing various applications along with examples of models for each.
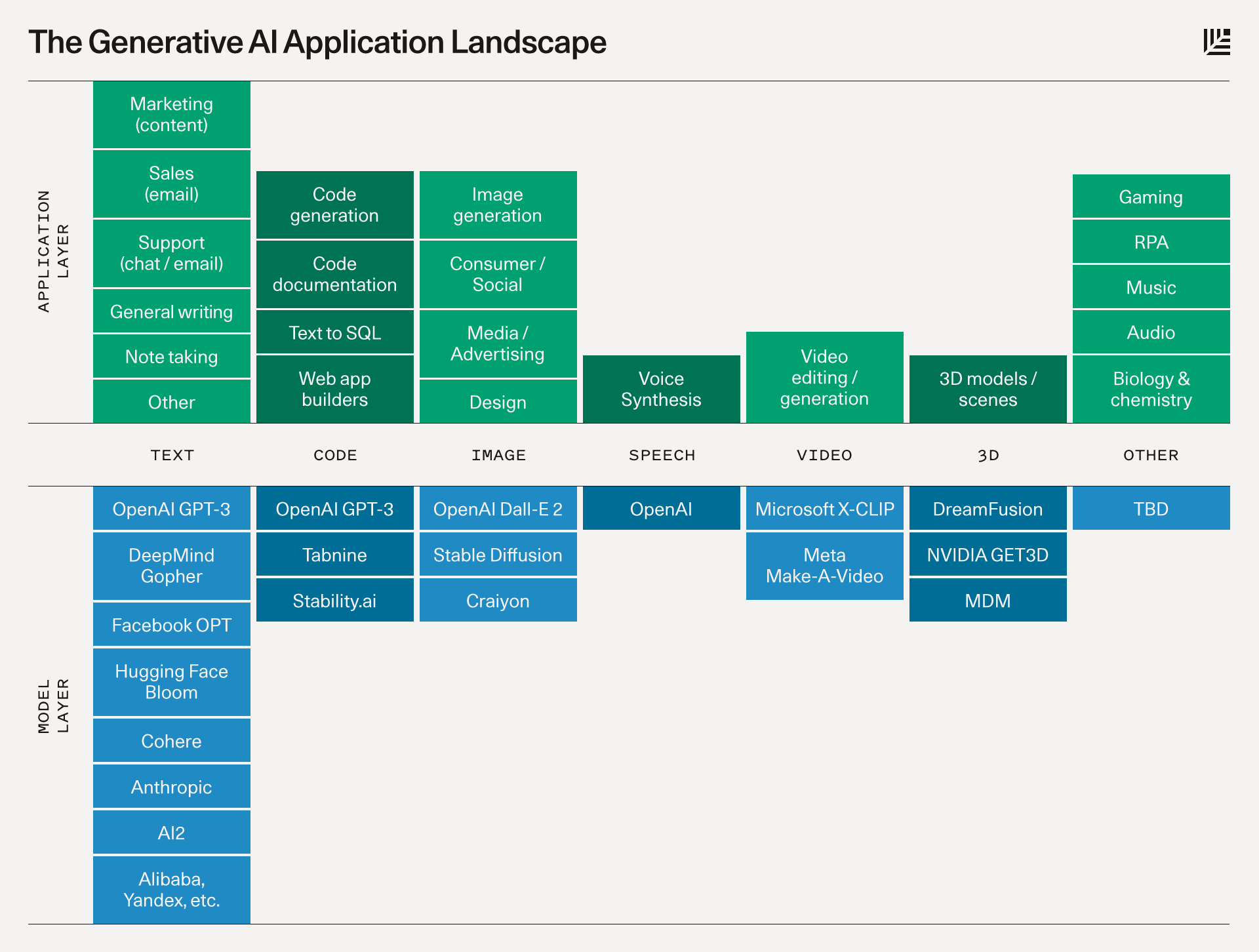
Sequoia Capital's round-up of the generative AI landscape from September 2022.
Specific applications currently under development utilizing generative AI models include the following:
Short-form, stylized copy is an excellent application of generative AI language models. The need for personalized copywriting content for websites, emails, social media platforms, and others is growing, with businesses looking for marketing strategies to generate sales. Generative AI has the potential to automate and augment effective copy while reducing the time and cost for businesses. In the future, ad copy could be automatically optimized for a target audience.
A prominent application of generative AI is the generation and translation of images. This includes creating fake images that look like real-world photographs. For example, Ted Karras, a research scientist at Nvidia, published a paper in 2017 demonstrating the ability to generate realistic images of human faces. The paper, titled "Progressive Growing of GANs for Improved Quality, Stability, and Variation," trained the model using real pictures of celebrities.

1024 x 1024 images of fake people generated by Karras et al. in their 2017 paper.
Other image applications include image-to-image translation and text-to-image translation. Image-to-image translation uses generative AI to transform one type of image into another. For example, transforming the style of the image and changing a photograph into the style of a famous artist or generating photo-realistic images based on sketches. Text-to-image translation produces visuals based on text inputs. Popular examples include Dall-e and Stable Diffusion.
Generative AI generating code has the potential to improve developer productivity. Estimates suggest that GitHub Copilot, an AI tool that turns natural language prompts into functional code, is generating almost 40 percent of the code written for projects where it is installed. Another opportunity lies in opening up coding to consumers without software development experience.
Generative AI can produce high-fidelity renderings from sketches and prompts to help the labor-intensive, iterative process of design and prototyping. As the field expands to 3D models, this opens up the potential for manufacturing and production text-to-model generation.
Large tech companies working on generative AI include the following:
- Microsoft has invested significantly in Open.AI, the San Francisco-based company behind GPT-3 and Dall-E 2
- Alphabet's Google and Deepmind Technologies releasing a large language model
- Meta plan to launch a generative AI video product
2022 saw significant investment in generative AI startups. Examples include Jasper ($125 million Series A) and Stability AI ($101 million seed funding). Jasper's new funding, announced in October 2022, values the company at $1.5 billion. Its investors include Insight Partners, Coatue, and Bessemer Venture Partners. The generative text tool for enterprise has grown to over 80,000 subscribers, with customers ranging from entrepreneurs to digital-marketing agencies and Fortune 500 companies. The company charges businesses to access its generative AI platform with prices based on the number of AI-assisted words generated. After its first full year of operations, Jasper had brought in $35 million in revenue. Stability AI launched an open-source text-to-image generator in August 2022 and has since been downloaded and licensed by over 200,000 software developers worldwide.
In a September 2022 post, Sequoia Capital stated:
The fields that generative AI addresses—knowledge work and creative work—comprise billions of workers. Generative AI can make these workers at least 10% more efficient and/or creative: they become not only faster and more efficient, but more capable than before. Therefore, Generative AI has the potential to generate trillions of dollars of economic value.


